- Published on
gRPC: How, Where, and Why You Should Use It
- Authors
- Name
- Usman Akhtar
- @usmanakhtar



What is RPC?
RPC, or Remote Procedure Call, is a network protocol that allows various programs or processes on different systems to communicate with one another. It enables one software to call a function or procedure on another remote machine and receive the results as if the function were running locally. This makes it easier to construct sophisticated programs made of various components that may be deployed across multiple devices.
There are many different implementations of RPC, with varying levels of complexity and features. Some popular implementations include:
- gRPC (Google’s RPC framework)
- Apache Thrift
- Microsoft’s Windows Communication Foundation (WCF)
However, the focus of this article will be primarily on gRPC.
What is gRPC?
gRPC is an open-source, high-performance remote procedure call (RPC) framework developed by Google. It is designed to enable client and server applications to communicate transparently and efficiently across different languages and platforms.
gRPC uses Protocol Buffers, a language-agnostic data serialization format, to define the interfaces and methods that are available on the server, which are then used to generate the client-side code. It supports many programming languages, including C++, Java, Python, Go, and many others.

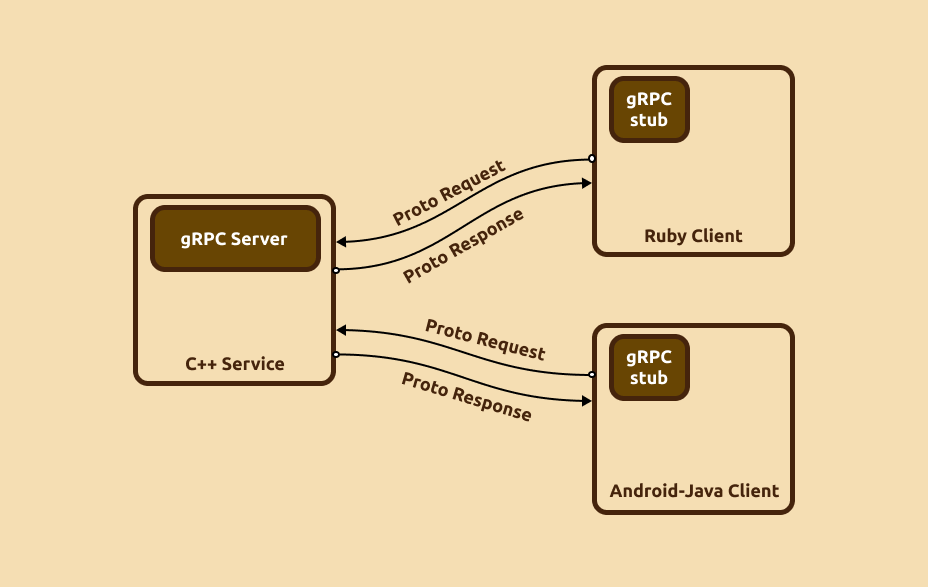
How does it work?
gRPC works by enabling communication between different services or applications over a network using Remote Procedure Calls (RPC). Here’s a simplified overview of how it works:
1. Service definition:
The first step in using gRPC is to define the service and methods that will be exposed by the server. This is done using Protocol Buffers, which provide a simple way to define the structure of the data that will be exchanged between the server and the client. A typical protobuf file looks like this:
syntax = "proto3";
message GreetingRequest {
string name = 1;
}
message GreetingResponse {
string message = 1;
}
service Greeter {
rpc SayHello(GreetingRequest) returns (GreetingResponse) {}
}
2. Code generation:
Once the service is defined, we need to make sure we copy the protobuf file created to the client and server and use gRPC to generate code both in the client and server in the programming language of choice. This code provides an interface for making RPC calls and handling incoming requests.
3. Client and server implementation:
The next step is to implement the client and server code using the generated interface. The client makes RPC calls to the server, and the server processes these requests and sends responses back to the client.
4. Data Serialization:
gRPC uses Protocol Buffers by default to serialize the data being sent and received over the network. This makes it faster and more efficient than other serialization formats like JSON.
5. Communication over the network:
The final step is to communicate over the network using gRPC. gRPC uses HTTP/2 as the underlying protocol, which provides features like multiplexing, flow control, and compression. This allows multiple RPC calls to be sent and received over a single connection, reducing overhead and improving performance.
Protobuf File
Let's suppose we have a JSON like this :
{
"name": "Alice",
"age": 30,
"gender": "FEMALE",
"interests": ["reading", "hiking"],
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA",
"zip": "12345"
}
}
Then protobuf file for such JSON will be like that:
syntax = "proto3";
// This is a simple example of a gRPC service that greets users.
// Define the request message for the SayHello method.
message GreetingRequest {
string name = 1;
int32 age = 2;
repeated string interests = 3;
Address address = 4;
}
// Define the response message for the SayHello method.
message GreetingResponse {
string message = 1;
}
// Define an enumeration for gender.
enum Gender {
UNKNOWN = 0;
MALE = 1;
FEMALE = 2;
}
// Define a nested message for address.
message Address {
string street = 1;
string city = 2;
string state = 3;
string zip = 4;
}
// Define the greeter service.
service Greeter {
// Sends a greeting to the server.
rpc SayHello(GreetingRequest) returns (GreetingResponse) {}
}
File Explanation:
Syntax:
Specifies the version of Protocol Buffer's syntax.
syntax = "proto3";
Comments:
Descriptive text that can be added to a Protocol Buffer file to provide additional context and documentation.
// This is a sample Protocol Buffers file for defining a Person message.
Message:
A message is a structured data type that contains a set of named fields with their corresponding data types. In this example, we have two messages: GreetingRequest and GreetingResponse.
Tags:
Numeric identifiers assigned to each field in a Protocol Buffer message that is used to identify and serialize the field.
message GreetingRequest {
string name = 1; //TAG = 1
int32 age = 2; //TAG = 2
repeated string interests = 3; //TAG = 3
Address address = 4; //TAG = 4
}
Scalar Types:
Basic data types such as integers, floats, and booleans that can be used to define the values of Protocol Buffer fields.
message GreetingRequest {
string name = 1; //Scalar Type = string
int32 age = 2; //Scalar Type = int32
repeated string interests = 3;
Address address = 4;
}
Fields:
In the protobuf file Fields define a piece of data that can be included in a message, and each field has a unique numeric identifier and a defined data type.
message GreetingRequest {
string name = 1; //Field
int32 age = 2; //Field
repeated string interests = 3; //Field
Address address = 4; //Field
}
Repeated Fields:
The repeated keyword is used to specify that a field is repeated. In this example, interests is repeated because a person can have multiple interests.
message GreetingRequest {
string name = 1; //Scalar Type = string
int32 age = 2; //Scalar Type = int32
repeated string interests = 3;
Address address = 4;
}
Enumerations:
A type of field in Protocol Buffers that restricts the possible values to a set of named constants.
enum Gender {
UNKNOWN = 0;
MALE = 1;
FEMALE = 2;
}
Nested Messages:
Protocol Buffers messages can contain other messages as fields, creating a hierarchy of data structures.
message GreetingRequest {
string name = 1;
int32 age = 2;
repeated string interests = 3;
Address address = 4;
}
message Address {
string street = 1;
string city = 2;
string state = 3;
string zip = 4;
}
Service:
A service is a set of related methods that can be called remotely using gRPC. In this example, we have a service called Greeter.
service Greeter {
// Sends a greeting to the server.
rpc SayHello(GreetingRequest) returns (GreetingResponse) {}
}
RPC:
An RPC is a remote procedure call, which is a method that can be called remotely using gRPC. In this example, we have a single RPC called SayHello, which takes a GreetingRequest as input and returns a GreetingResponse.
service Greeter {
// Sends a greeting to the server.
rpc SayHello(GreetingRequest) returns (GreetingResponse) {}
}
Pros And Cons Of Protocol Buffers:
Pros:
Smaller Payload Size:
Protocol Buffers use a binary format that is more compact than JSON, resulting in smaller message payloads. This can lead to faster data transfer times, lower network bandwidth usage, and reduced storage requirements.
Faster Serialization and Deserialization:
Protocol Buffers are designed to be fast and efficient, with a simple and optimized serialization and deserialization process. This can result in improved performance over JSON, especially in high-volume or low-latency applications.
Strongly Typed Schema:
Protocol Buffers use a strongly typed schema that allows for easier validation and type checking of messages. This can help catch errors earlier in the development process, and can also make it easier to work with the data in your application.
Backward Compatibility:
Protocol Buffers are designed to be forward and backward-compatible, which means that you can evolve your schema over time without breaking existing clients or servers. This can make it easier to maintain and evolve your application over time, while also reducing the risk of breaking changes.
Code Generation:
Protocol Buffers can be used to generate language-specific code that makes it easier to work with the data in your application. This can save time and reduce errors, especially when working with complex or structured data.
Efficient Encoding and Decoding:
Protocol Buffers use a binary encoding that can be more efficient and faster to encode and decode than JSON, especially for larger messages or when working with high-volume data.
Automatic Validation:
Because Protocol Buffers use a strongly typed schema, you can perform automatic validation of messages to ensure that they conform to the expected format. This can help catch errors earlier in the development process, reduce bugs, and improve overall code quality.
Cons:
Binary Format:
Protocol Buffers use a binary format that can be more difficult to read and debug than plain text formats like JSON. This can make it harder to troubleshoot issues in your data or messages, especially for those who are not familiar with the format.
Additional Tooling and Infrastructure:
In order to use Protocol Buffers effectively, you may need to invest in additional tooling and infrastructure, such as code generators or libraries, to work with the format. This can add to the complexity and overhead of your application.
How to manage Protobufs?
In gRPC, the Protocol Buffer schema file (usually with the .proto file extension) defines the structure of the data that is exchanged between the client and server. This schema file needs to be available to both the client and the server in order for them to communicate effectively.
Typically, you will have a single copy of the .proto file that defines the message types and services used in your application, and this file will be used to generate the client and server code in the appropriate programming language. The generated code includes the necessary classes and methods for serializing and deserializing the message data, and it also includes the gRPC server and client stubs.
So, while the .proto file does need to be available to both the client and server, you don't necessarily need to copy it to every server. Instead, you can share the file between the client and server, some of the ways it can be done are:
Version Control System:
One common way to share schema files is to store them in a version control system (such as Git) and have the client and server retrieve the file from the same repository. This allows for easy versioning and collaboration and ensures that both the client and server are using the same version of the schema file.
Shared Directory:
Another approach is to store the schema file in a shared directory that is accessible to both the client and server. This directory could be on a shared network drive, in a cloud storage service, or on a shared file system. This method is simple to implement but may be less secure than using a version control system.
Package Manager:
Some programming languages have package managers (such as NuGet for .NET, npm for Node.js, or PyPI for Python) that can be used to distribute and install gRPC libraries, including the .proto file. This can simplify the process of sharing schema files and ensure that the correct version of the file is used by all parties.
Third Part Services:
Using some services like ProtoPie, which provides a cloud-based service for managing and sharing schema files, as well as generating client and server code in a variety of programming languages, or gRPC Gateway, which provides a RESTful API gateway for gRPC services.